HASHING TECHNIQUES:
- Hashing provides very fast access to records on certain search conditions. This organization is usually called a hash file.
- The search condition must be an equality condition on a single field, called the hash field of the file. The hash field is also called as hash key.
- The idea behind hashing is to provide a function ‘h’ called a hash function (or) randomizing function, that is applied to the hash field value of a record and yields the address of the disk block in which the record is stored.
- Hashing is also used as an internal search within a program whenever a group of records is accessed or exclusively by using the value of one field.
Static Hashing
- A bucket is a unit of storage containing one or more records (a bucket is typically a disk block).
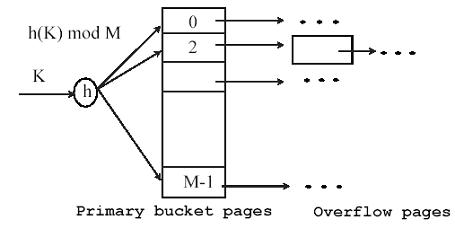
- The file blocks are divided into M equal-sized buckets, numbered bucket0, bucket1... bucketM-1.Typically, a bucket corresponds to one (or a fixed number of) disk block.
- In a hash file organization we obtain the bucket of a record directly from its search-key value using a hash function, h (K).
- The record with hash key value K is stored in bucket, where i=h(K).
- Hash function is used to locate records for access, insertion as well as deletion.
- Records with different search-key values may be mapped to the same bucket; thus entire bucket has to be searched sequentially to locate a record.
- primary pages fixed, allocated sequentially, never de-allocated; overflow pages if needed.
h(K) mod M = bucket to which data entry with key k belongs. (M = # of buckets)
Static External Hashing
- One of the file fields is designated to be the hash key, K, of the file.
- Collisions occur when a new record hashes to a bucket that is already full.
- An overflow file is kept for storing such records. Overflow records that hash to each bucket can be linked together.
- To reduce overflow records, a hash file is typically kept 70-80% full.
- The hash function h should distribute the records uniformly among the buckets; otherwise, search time will be increased because many overflow records will exist.
Static Hashing (Contd.)
- Hash function works on search key field of record r. Must distribute values over range 0 ... M-1.
H (K) = (a * K + b) usually works well.
a and b are constants;
lots known abut how to tune h.
- Typical hash functions perform computation on the internal binary representation of the search-key.
For example, for a string search-key, the binary
representations of all the characters in the string could be added and the sum modulo the number of buckets could be returned. .
- Ideal hash function is random, so each bucket will have
the same number of records assigned to it irrespective of
the actual distribution of search-key values in the file.
Dynamic and Extendible Hashing Techniques
- Hashing techniques are adapted to allow the dynamic growth and shrinking of the number of file records.
These techniques include the following:
- Dynamic hashing
- Extendible hashing
- Linear hashing.
- These hashing techniques use the binary representation of the hash value h(K).
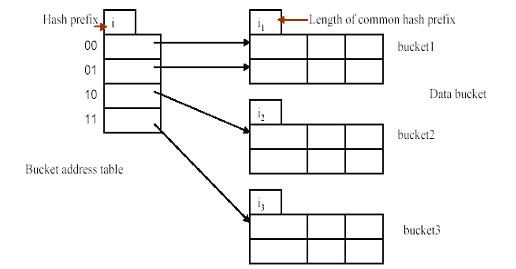
- In dynamic hashing the directory is a binary tree.
- In extendible hashing the directory is an array of size 2d where d is called the global depth.
- The directories can be stored on disk, and they expand or shrink dynamically. Directory entries point to the disk blocks that contain the stored records.
- An insertion in a disk block that is full causes the block to split into two blocks and the records are redistributed among the two blocks.
- The directory is updated appropriately.
- Dynamic and extendible hashing do not require an overflow area.
- Linear hashing does require an overflow area but does not use a directory. Blocks are split in linear order as the file expands.
Dynamic Hashing
- Good for database that grows and shrinks in size
- Allows the hash function to be modified dynamically
Extendable hashing – one form of dynamic hashing
- Hash function generates values over a large range —typically b-bit integers, with b = 32.
- At any time use only a prefix of the hash function to index into a table of bucket addresses.
- Let the length of the prefix be i bits, 0 _ i _ 32.
- Bucket address table size = 2i. Initially i = 0
- Value of i grows and shrinks as the size of the database grows and shrinks.
- Multiple entries in the bucket address table may point to a bucket.
- Thus, actual number of buckets is < 2i
- The number of buckets also changes dynamically due to coalescing and splitting of buckets.
General Extendable Hash Structure
Linear Hashing
- This is another dynamic hashing scheme, an alternative to Extendible Hashing.
- LH handles the problem of long overflow chains without using a directory, and handles duplicates.
- Idea: Use a family of hash functions h0, h1, h2,...
hi(key) = h(key) mod(2iN); N = initial # buckets
h is some hash function (range is not 0 to N-1)
If N = 2d0, for some d0, hi consists of applying h and looking at the last di bits, where di = d0 + i.
hi+1 doubles the range of hi (similar to directory doubling)