Deadlock detection is the process of actually determining that a deadlock exists and identifying the processes and resources involved in the deadlock.
The basic idea is to check allocation against resource availability for all possible allocation sequences to determine if the system is in deadlocked state a. Of course, the deadlock detection algorithm is only half of this strategy. Once a deadlock is detected, there needs to be a way to recover several alternatives exists:
- Temporarily prevent resources from deadlocked processes.
- Back off a process to some check point allowing preemption of a needed resource and restarting the process at the checkpoint later.
- Successively kill processes until the system is deadlock free.
These methods are expensive in the sense that each iteration calls the detection algorithm until the system proves to be deadlock free. The complexity of algorithm is O (N2) where N is the number of proceeds. Another potential problem is starvation; same process killed repeatedly.
Deadlock detection
If there is only one instance of each resource, it is possible to detect deadlock by constructing a resource allocation/request graph and checking for cycles. Graph theorists have developed a number of algorithms to detect cycles in a graph.
A cycle detection algorithm
For each node N in the graph
- Initialize L to the empty list and designate all edges as unmarked
- Add the current node to L and check to see if it appears twice. If it does, there is a cycle in the graph.
- From the given node, check to see if there is any unmarked outgoing edges. If yes, go to the next step, if no, skip the next step.
- Pick an unmarked edge, mark it, and then follow it to the new current node and go to step 3.
- If a dead end is reached, Go back to the previous node and make that the current node. If the current node is the starting Node and there are no unmarked edges, there are no cycles in the graph. Otherwise, go to step 3.
Consider an example with five processes and five resources. Here is the resource request/allocation graph.
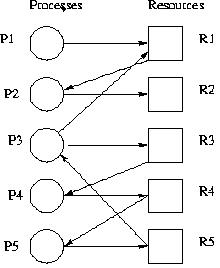
The algorithm needs to search each node; let's start at node P1. Add P1 to L and follow the only edge to R1, marking that edge. R1 is now the current node then adds that to L, check to confirm that it is not already in. Then follow the unmarked edge to P2, marking the edge, and making P2 the current node. Add P2 to L, check to make sure that it is not already in L, and follow the edge to R2. This makes R2 the current node, and then adds it to L, check to make sure that it is not already there. If the node at a dead end then back up, making P2 the current node again. There are no more unmarked edges from P2 so back up yet again, making R1 the current node. There are no more unmarked edges from R1 so back up yet again, making P1 the current node. Since there are no more unmarked edges from P1 and since this was the starting point.
Move to the next unvisited node P3, and initialize L to empty. First follow the unmarked edge to R1, putting R1 on L. Continuing, make P2 the current node and then R2. Since it is a dead end, repeatedly back up until P3 becomes to the current node again.
L now contains P3, R1, P2, and R2. P3 is the current node, and it has another unmarked edge to R3. Make R3 the current node, add it to L, and follow its edge to P4. Repeat this process, visiting R4, then P5, then R5, then P3. When P3 is visited again note that it is already on L, so a cycle has detected, meaning that there is a deadlock situation.
Once deadlock has been detected, it is not clear what the system should do to correct the situation. There are three strategies.
- Preemption - Take an already allocated resource away from a process and give it to another process. This can present problems. Suppose the resource is a printer and a print job is half completed. It is often difficult to restart such a job without completely starting over.
- Rollback - In situations where deadlock is a real possibility, the system can periodically make a record of the state of each process and when deadlock occurs, roll everything back to the last checkpoint, and restart, but allocating resources differently so that deadlock does not occur. This means that all work done after the checkpoint is lost and will have to be redone.
- Kill one or more processes - this is the simplest and crudest, but it works.